

Using historical codebase to build an eval suite
How thousands of pull requests let Fractional automate annotating a ground truth set for a new product.

Zapier has millions of users using thousands of integrations with different platforms. They’re constantly requesting new features they’d like to see, and Zapier has a team dedicated to identifying the most popular and useful, and implementing them to expand their API catalog.
To make this team more productive, Fractional and Zapier implemented a system that pre-populates the tickets with information about the relevant APIs, as well as suggested code, to give them a head start. For example, if a feature request on an integration for a photo platform suggested adding a map to show location information for the photo, the integration would find the endpoint that could provide that information, link to the documentation, and suggest how to use it. (See below to see what this looks like in Zapier’s ticketing system.)
But a critical part of any LLM system is ensuring the answers it provides are reliable and correct.
Doing so here would require hundreds of annotated tickets and verified information about which endpoints best implemented solutions for them.
Building a good data set is absolutely necessary, but would take a huge amount of engineer time away from actually building solutions. On reflection, though, we had the best possible data set already existing: Zapier’s historical ticket database.
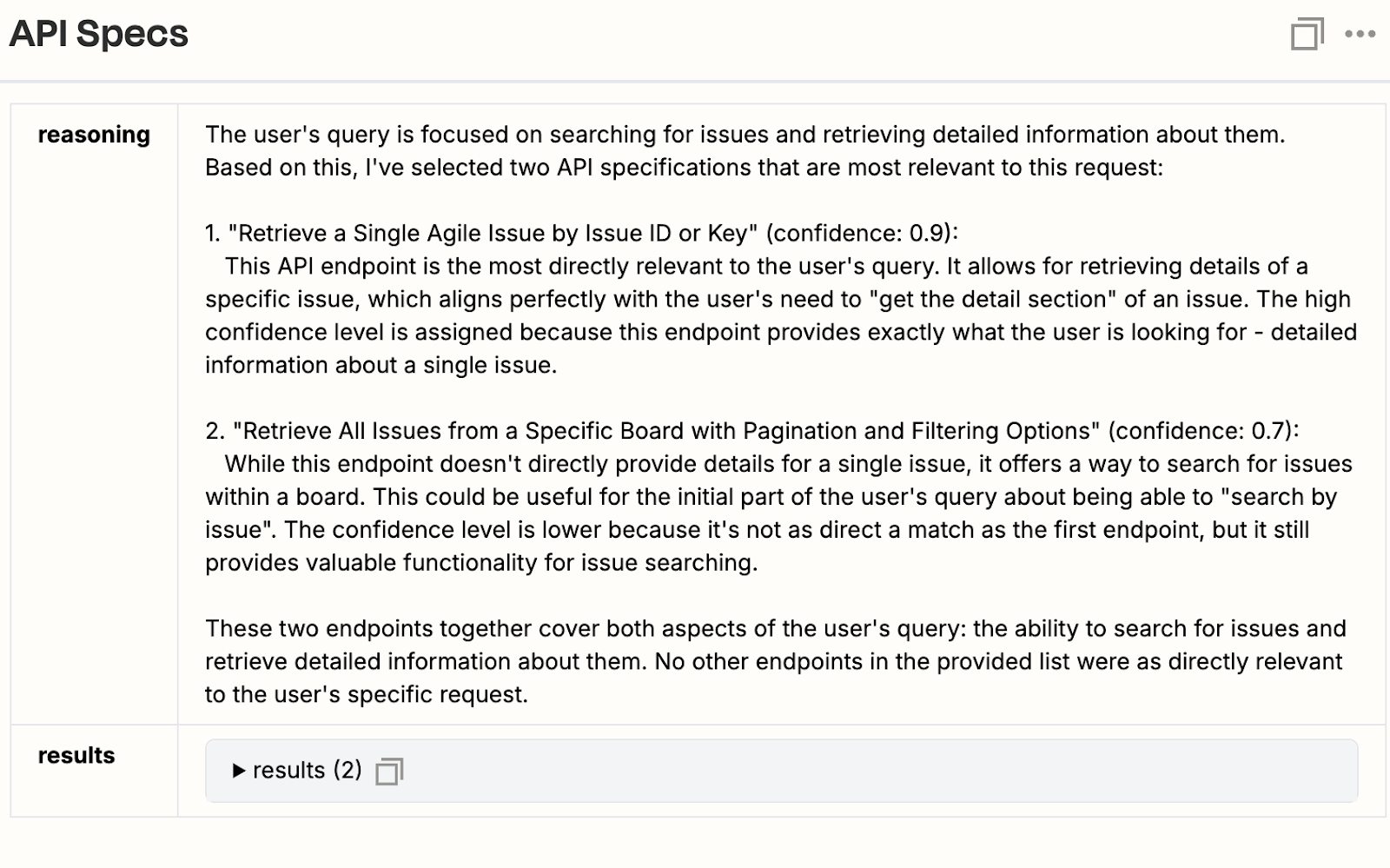
Once we realized this, we decided the following questions defined correctness:
Do the endpoints the user needs appear in the top five results?
Does the endpoint the user most needs show up as the top result?
Historical tickets are the perfect source for a validation set, because by definition they’re successful solutions to exactly the problem we automated. To harvest historical tickets to use, we selected tickets that:
Are closed (meaning there is code resolving the issue)
Are new actions (so no corrections of old actions, which would be partial solutions)
Have an associated merge request.
Then, we paired these tickets to matching gitlab merge requests giving us a description of a change paired with the code added based on that description. From the code we used an LLM to extract the endpoints that ended up being used, and our suite was ready to use.
A few hundred test cases provided a robust evaluation framework, allowing us to quickly iterate on making the specification search more useful to developers working on net new actions.
This will allow Zapier’s internal developers to quickly find and integrate endpoints they need based on their tickets. Once we have confidence that this step is working well, we will even be able to suggest codge changes so that all the internal engineer has to do is test the changes.
Building an eval suite by hand would have taken a huge amount of valuable engineer time. By leveraging historical data, we were able to rigorously build in an evaluation suite.




