

On the new larger context windows
Search for a command to run...
No comments yet. Be the first to comment.
Prompt engineering is iteration. You read what failed, tweak the prompt, run it again, repeat. It's a tedious, but inextricable, part of building with LLMs. GEPA (Genetic-Pareto) takes that loop off y

What AI engineers need to know from the past two weeks — picked by Fractional AI.

While building an agent for a client, we hit a scaling problem: a coordinator agent had 4-5 subagents each with 15-20 tool calls. Each tool result got appended to the context, then what started as a r

Top links and resources from Fractional AI, curated for AI engineers.

On defaulting to chat as the interface for AI products — and why it's holding you back.

Today the latest LLMs have large context windows up to ~1 million tokens. There are many occasions when this larger context window can be useful:
Context engineering: injecting rich system/user context without juggling state
Long documents: reading full transcripts and reports end-to-end
Code comprehension: scanning entire repositories to answer questions
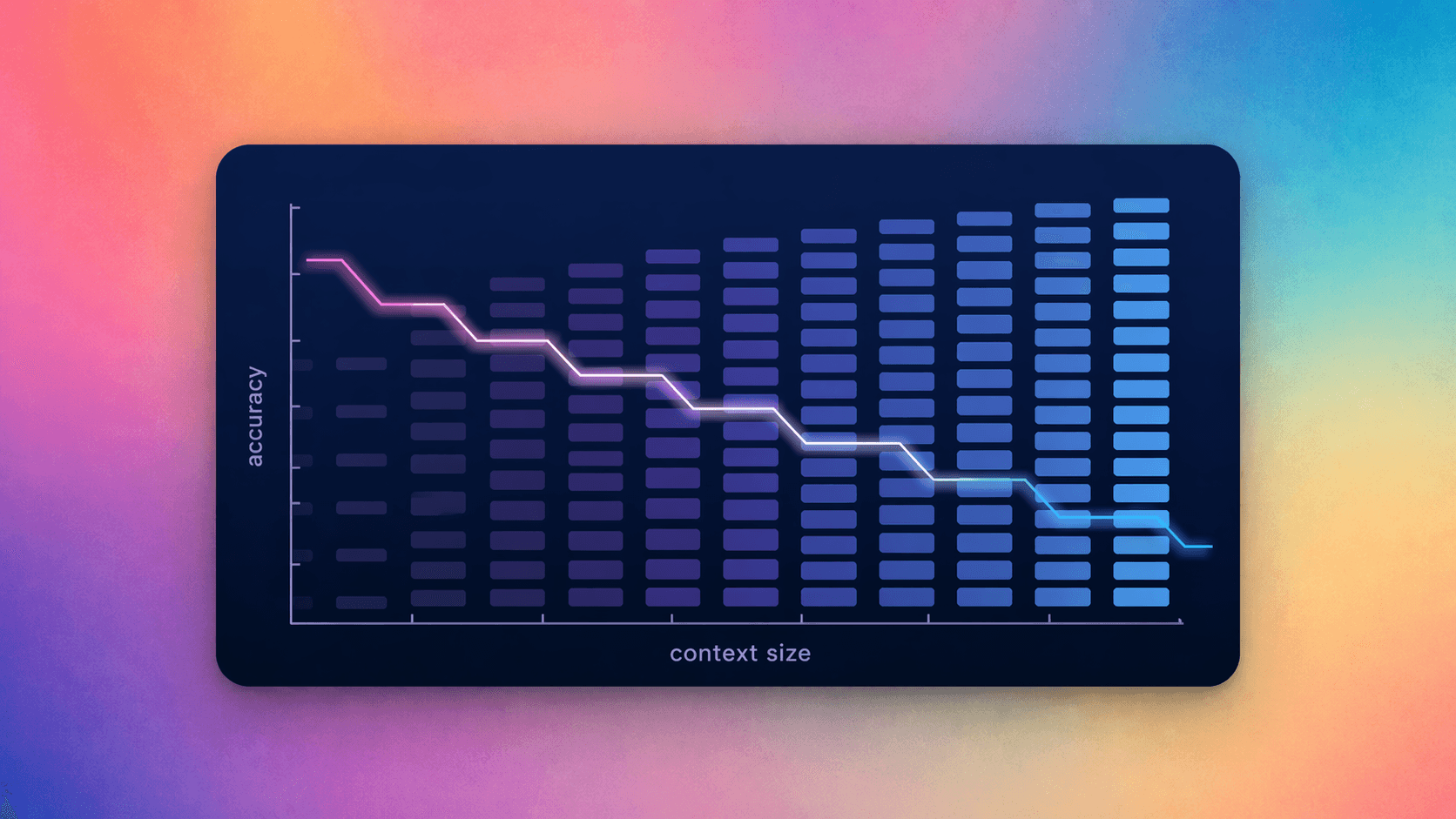
But in our testing, using more input tokens often hurts accuracy. At Fractional, we built GridCheck Bench, an internal evaluation that measures the accuracy–cost trade-off across tabular inputs. In the eval we ask the LLM to find factual answers to questions from a table that has 100s of columns per row. The chart below shows how accuracy changes — while using the YAML input format — as we change the number of input rows

As you can see in the graph, The model still “reads” more, but it answers correctly less often. We see this all the time at Fractional, from parsing API documentation to assembling complex objects. Here are some techniques we’ve used to mitigate the performance losses from larger context windows:
Breaking up the input query into chunks and resolving each section individually (for example, in this experiment we could break up the input into chunks of say 100 for GPT-5 and have the LLM tell us if the answer was in each chunk. Another classic use of this is /compact on calude code)
Start cutting out information and/or context from the prompt and carefully figure out what pieces of information are improving performance and which pieces you can leave out (Imagine you have 10 different pieces of information that you send to your prompt each of which takes between 100-10000 tokens, you could measure the performance of your prompt when you remove each of these pieces individually and leave out any which don’t have too big of a performance hit)
Creating useful tools for the LLM to produce answers deterministically to your problem (a trivial example: if you are adding up thousands of numbers don’t ask the llm for the sum – have it send the problem to a tool to run a calculation. A less trivial example: if adding a new user requires 5 separate API calls giving the LLM a tool to call all 5 at once will reduce the possibility for error— see here for more information on designing your API access patterns for LLMs)